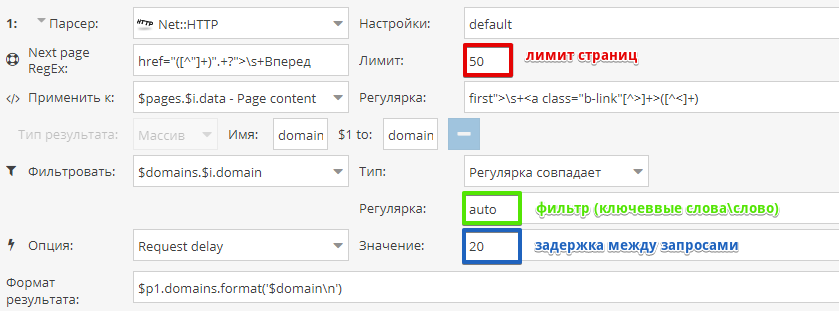
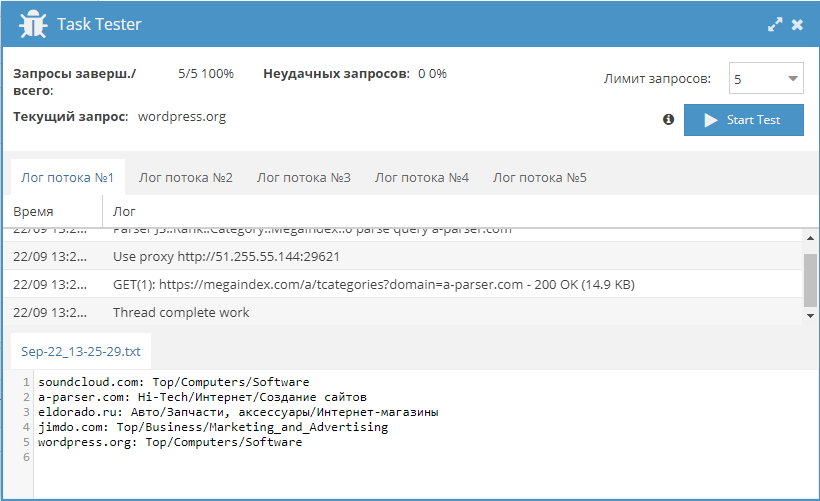
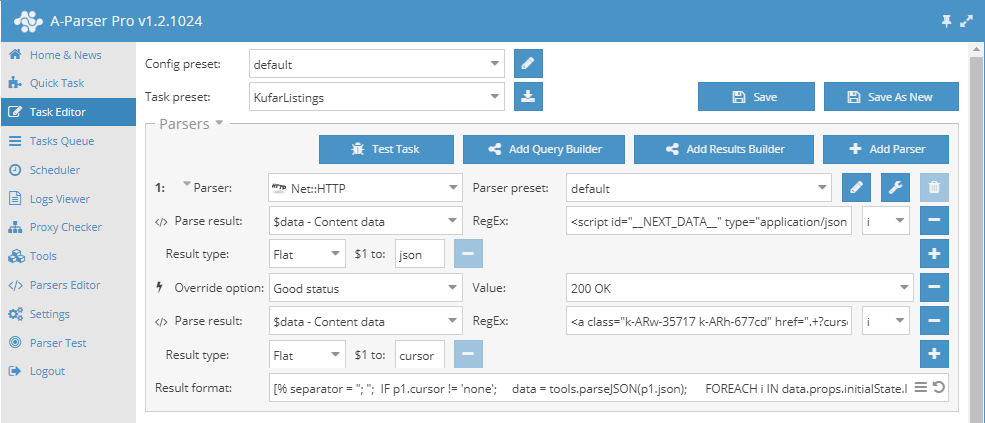
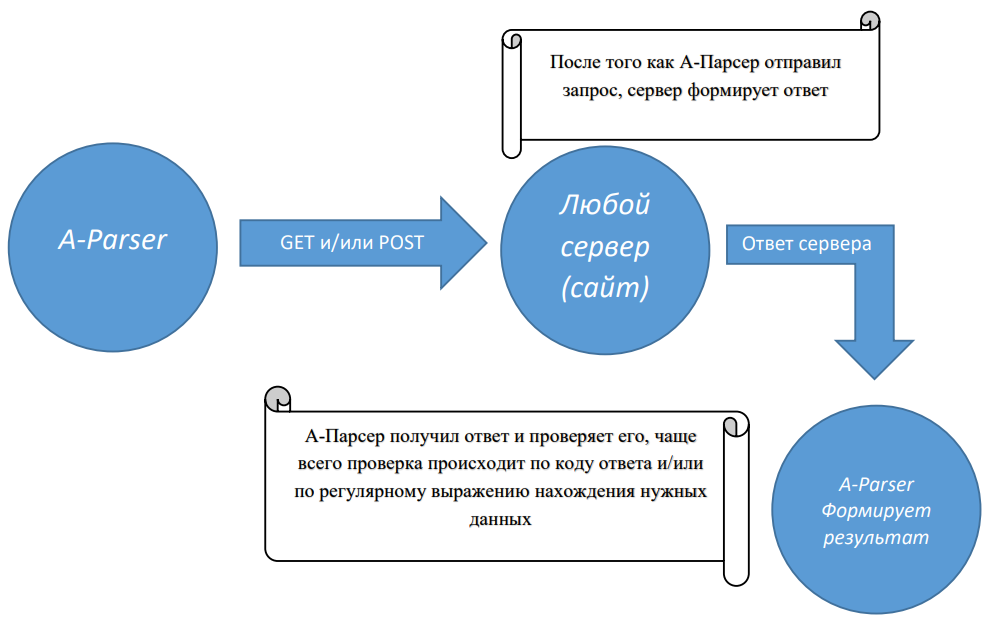
1.2.948 - новые парсеры SecurityTrails IP и Domain, поддержка доменных прокси, множество исправлений

Улучшения
* Добавлен парсер Rank::MOZ.
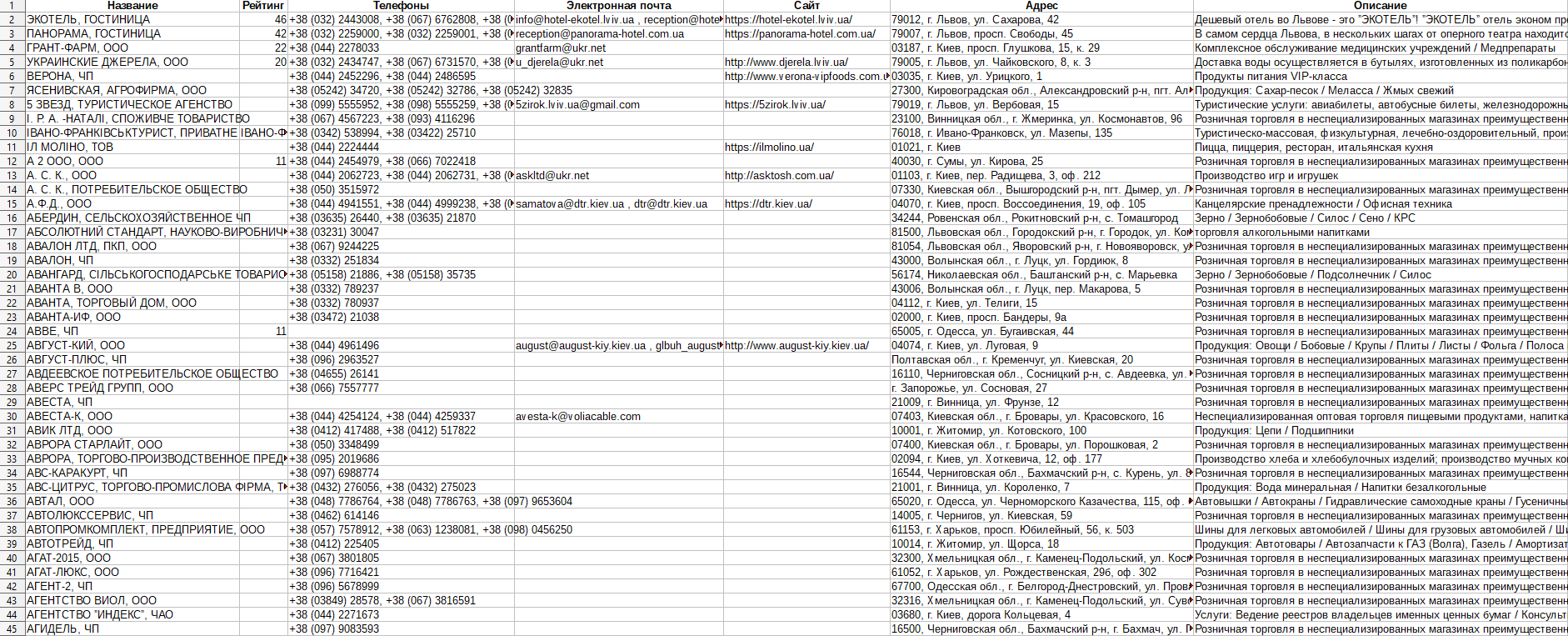
Собираемые данные: вся информация, содержащаяся на странице.
* Добавлены парсеры SecurityTrails::Domain и SecurityTrails::IP.
Для работы парсеров необходимо указать пресет Util::ReCaptcha2.
- SecurityTrails::IP
В качестве запроса следует указывать ipv4 адрес.
Собирает домены по IP и информацию о них.
- SecurityTrails::Domain
В качестве запроса следует указывать домен, например a-parser.com.
Собираемые данные:
- Данные по DNS
- Список технологий, используемых на сайте (движки и проч.)
- Список открытых портов
- Alexa rank
- Страна
- Хостер
- Даты начала и окончания регистрации
- Whois статус
- Регистратор
- Список исторических данных по DNS
- Список субдоменов
* Добавлена возможность отключать валидацию TLS сертификатов.
* Добавлена поддержка доменных прокси.
Исправления в связи с изменениями в выдаче
* Исправлен парсинг новостей в SE::Google.
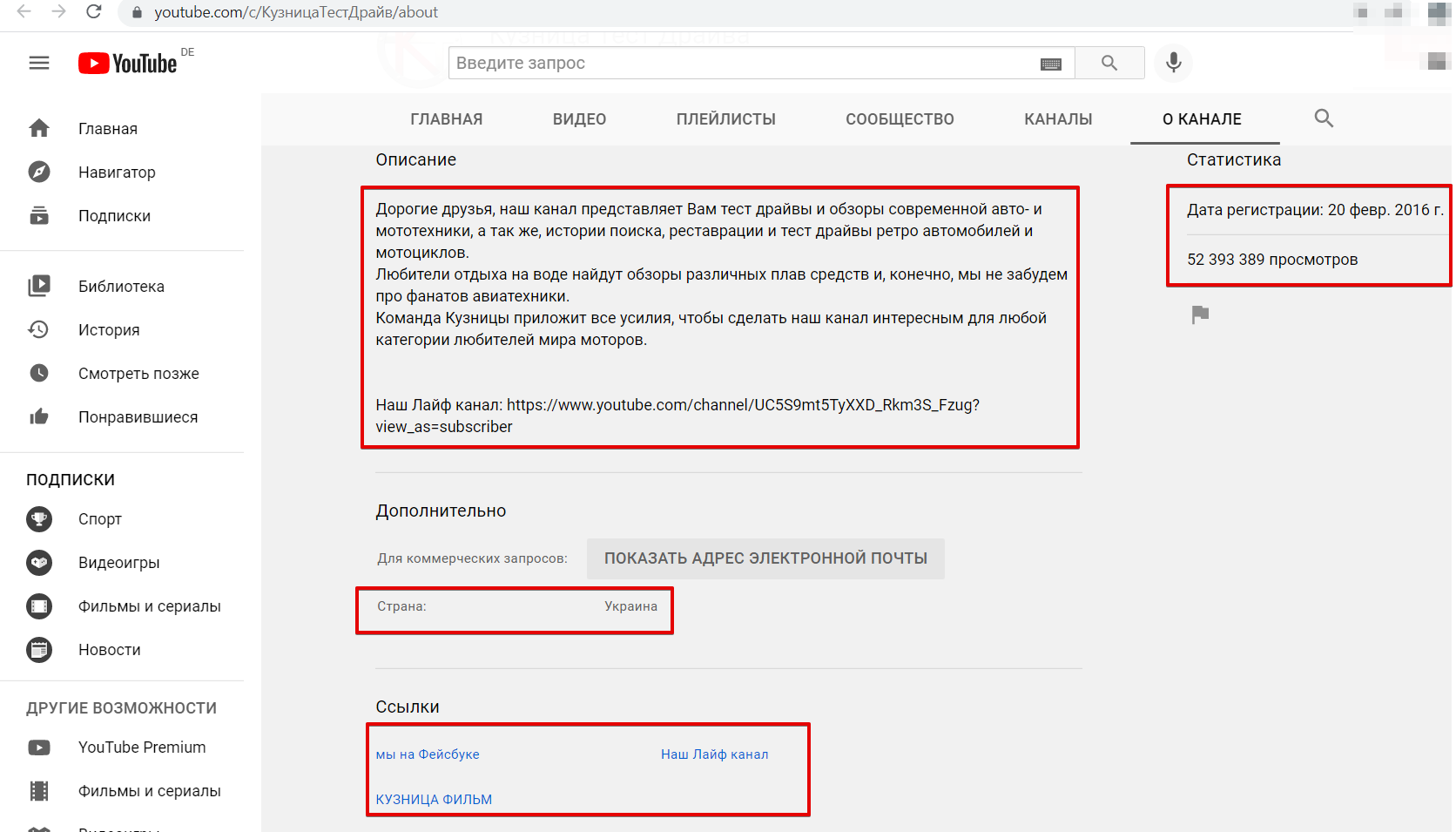
* Исправлен Social::Instagram::Profile.
* Исправления в SE::Yandex:
- исправлен парсинг турбо ссылок;
- исправлен парсинг новостных сниппетов.
* Исправления в SE::Google, SE::Baidu, SE::Yandex::Direct, Shop::Yandex::Market.
* Исправления в SE::Yahoo - ошибка в выборе стран, у которых одинаковый домен, восстановлен парсинг сниппетов.
Исправления
* Исправлена ошибка в алгоритме автовыбора домена в SE::Yandex.
* Исправлена работа Rank::MajesticSEO, SE::Bing::Translator.
* Исправлена ошибка, если файл config.txt был сохранен в кодировке utf-8 с BOM (парсер некорректно читал файл).
* Решена проблема с переопределениями опций в парсере HTML::LinkExtractor.
* NodeJS: новые установленные модули теперь доступны до перезагрузки A-Parser'a.
* Исправлено падение парсера при вызове метода getProxies.

Улучшения
* Добавлен парсер Rank::MOZ.
Собираемые данные: вся информация, содержащаяся на странице.
* Добавлены парсеры SecurityTrails::Domain и SecurityTrails::IP.
Для работы парсеров необходимо указать пресет Util::ReCaptcha2.
- SecurityTrails::IP
В качестве запроса следует указывать ipv4 адрес.
Собирает домены по IP и информацию о них.
- SecurityTrails::Domain
В качестве запроса следует указывать домен, например a-parser.com.
Собираемые данные:
- Данные по DNS
- Список технологий, используемых на сайте (движки и проч.)
- Список открытых портов
- Alexa rank
- Страна
- Хостер
- Даты начала и окончания регистрации
- Whois статус
- Регистратор
- Список исторических данных по DNS
- Список субдоменов
* Добавлена возможность отключать валидацию TLS сертификатов.
* Добавлена поддержка доменных прокси.
Исправления в связи с изменениями в выдаче
* Исправлен парсинг новостей в SE::Google.
* Исправлен Social::Instagram::Profile.
* Исправления в SE::Yandex:
- исправлен парсинг турбо ссылок;
- исправлен парсинг новостных сниппетов.
* Исправления в SE::Google, SE::Baidu, SE::Yandex::Direct, Shop::Yandex::Market.
* Исправления в SE::Yahoo - ошибка в выборе стран, у которых одинаковый домен, восстановлен парсинг сниппетов.
Исправления
* Исправлена ошибка в алгоритме автовыбора домена в SE::Yandex.
* Исправлена работа Rank::MajesticSEO, SE::Bing::Translator.
* Исправлена ошибка, если файл config.txt был сохранен в кодировке utf-8 с BOM (парсер некорректно читал файл).
* Решена проблема с переопределениями опций в парсере HTML::LinkExtractor.
* NodeJS: новые установленные модули теперь доступны до перезагрузки A-Parser'a.
* Исправлено падение парсера при вызове метода getProxies.

 ) - отписывайтесь
) - отписывайтесь