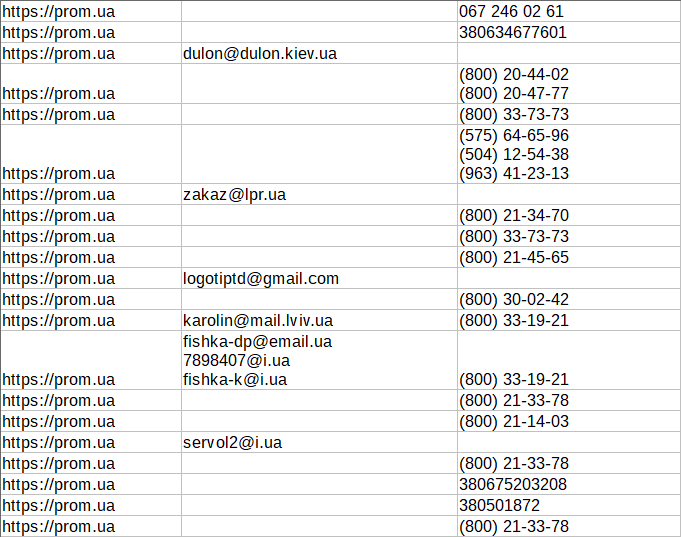
[URL=https://a-parser.com/threads/5523/][B]1.2.570 - новые парсеры API::Server::Redis и SE::Startpage, улучшения в существующих парсерах[/B][/URL]
[IMG]https://files.a-parser.com/img/1.2.570.png[/IMG]
[B]Улучшения[/B]
[LIST]
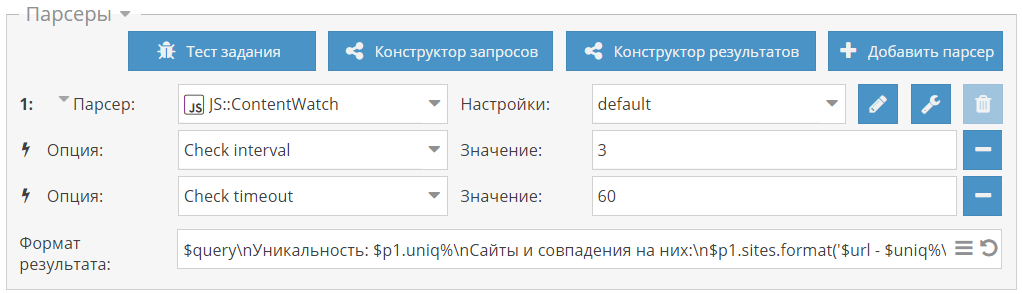
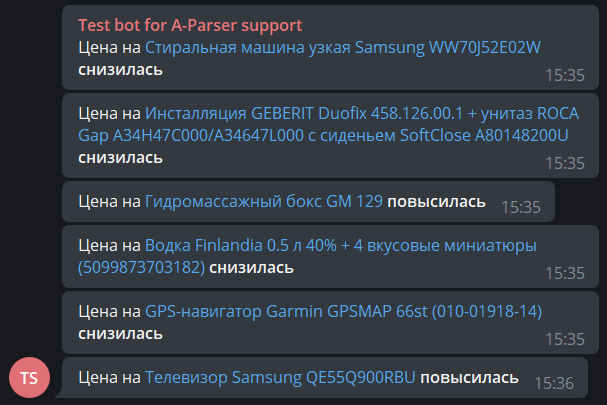
[*]Добавлен новый парсер API::Server::Redis (только для лицензий Enterprise)
[*]В [IMG]https://a-parser.com/img/parsers/se-google.png[/IMG][URL=https://a-parser.com/wiki/se-google-modern/]SE::Google::Modern[/URL] добавлена возможность определять наличие расширенных сниппетов (rich snippets) в выдаче
[*]В связи с изменениями на сервисе-источнике парсер SE::IxQuick был удален, а вместо него добавлен SE::Startpage с почти аналогичным функционалом
[*]Улучшена логика работы функции Get full links в SE::Baidu SE::Baidu
[*]В [IMG]https://a-parser.com/img/parsers/se-google.png[/IMG][URL=https://a-parser.com/wiki/se-google-modern/]SE::Google::Modern[/URL] реализована возможность указывать дополнительные заголовки для запросов
[*]Улучшен парсинг меток сайтов в [IMG]https://a-parser.com/img/parsers/se-yandex.png[/IMG][URL=https://a-parser.com/wiki/se-yandex/]SE::Yandex[/URL], а также добавлена поддержка новых типов меток
[*]Улучшена логика работы функции Get full links в SE::Baidu
[*]Оптимизирован алгоритм обработки подзапросов
[/LIST]
[B]Исправления в связи с изменениями в выдаче[/B]
[LIST]
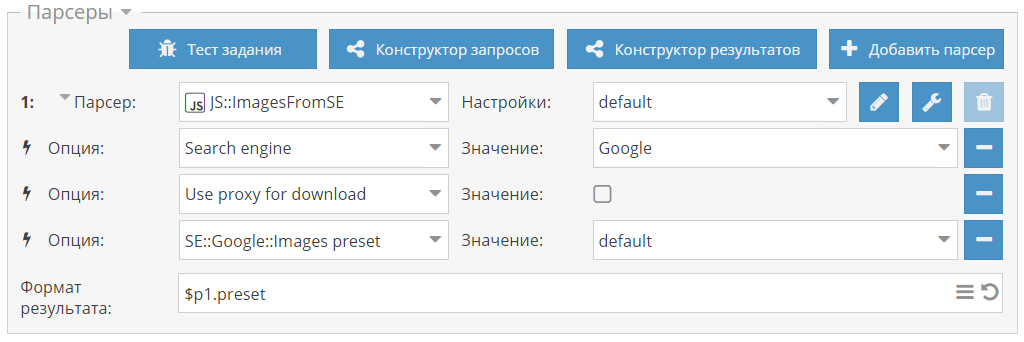
[*]Улучшена работа [IMG]https://a-parser.com/img/parsers/se-youtube.png[/IMG][URL=https://a-parser.com/wiki/se-youtube/]SE::YouTube[/URL], в связи с тестированием новой верстки
[*]В [IMG]https://a-parser.com/img/parsers/se-google-translate.png[/IMG][URL=https://a-parser.com/wiki/se-google-translate/]SE::Google::Translate[/URL] переработан механизм повторных попыток, добавлена поддержка сессий
[*]Исправлен парсинг сниппетов в [IMG]https://a-parser.com/img/parsers/se-google-images.png[/IMG][URL=https://a-parser.com/wiki/se-google-images/]SE::Google::Images[/URL]
[*]Поностью переработан [IMG]https://a-parser.com/img/parsers/googleplay-apps.png[/IMG][URL=https://a-parser.com/wiki/googleplay-apps/]GooglePlay::Apps[/URL]- теперь он парсит только первую страницу результатов
[*]Исправлен парсинг мобильной выдачи в SE::Google::Modern
[*]Исправлена работа [IMG]https://a-parser.com/img/parsers/se-seznam.png[/IMG][URL=https://a-parser.com/wiki/se-seznam/]SE::Seznam[/URL] при отсутствии результатов
[*]Исправлена работа [IMG]https://a-parser.com/img/parsers/rank-linkpad.png[/IMG][URL=https://a-parser.com/wiki/rank-linkpad/]Rank::Linkpad[/URL], парсер полностью переписан
[*][IMG]https://a-parser.com/img/parsers/se-bing-translator.png[/IMG][URL=https://a-parser.com/wiki/se-bing-translator/]SE::Bing::Translator[/URL], [IMG]https://a-parser.com/img/parsers/se-duckduckgo-images.png[/IMG][URL=https://a-parser.com/wiki/se-duckduckgo-images/]SE:: DuckDuckGo::Images[/URL], [IMG]https://a-parser.com/img/parsers/se-bing-images.png[/IMG][URL=https://a-parser.com/wiki/se-bing-images/]SE::Bing::Images[/URL]
[/LIST]
[B]Исправления[/B]
[LIST]
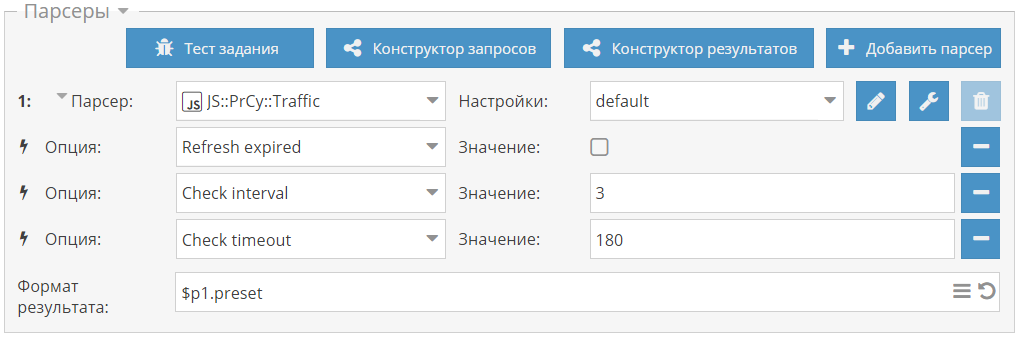
[*]Исправлена проблема, из-за которой в некоторых случаях при запросе через API возвращался пустой массив страниц
[*]Исправлено падение скорости в [IMG]https://a-parser.com/img/parsers/net-whois.png[/IMG][URL=https://a-parser.com/wiki/net-whois/]Net::Whois[/URL]
[*]Исправлен баг в оптимизации парсеров
[*]Исправлено сохранение параметра Report period в [IMG]https://a-parser.com/img/parsers/se-yandex-direct-frequency.png[/IMG][URL=https://a-parser.com/wiki/se-yandex-direct-frequency/]SE::Yandex:: Direct::Frequency[/URL]
[*]В [IMG]https://a-parser.com/img/parsers/html-linkextractor.png[/IMG][URL=https://a-parser.com/wiki/html-linkextractor/]HTML::LinkExtractor [/URL]исправлен сбор ссылок, если в них есть перенос строки
[/LIST]
[URL=https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ][IMG]https://files.a-parser.com/img/button_a-parser_small_550.png[/IMG][/URL]
[IMG]https://files.a-parser.com/img/1.2.570.png[/IMG]
[B]Улучшения[/B]
[LIST]
[*]Добавлен новый парсер API::Server::Redis (только для лицензий Enterprise)
[*]В [IMG]https://a-parser.com/img/parsers/se-google.png[/IMG][URL=https://a-parser.com/wiki/se-google-modern/]SE::Google::Modern[/URL] добавлена возможность определять наличие расширенных сниппетов (rich snippets) в выдаче
[*]В связи с изменениями на сервисе-источнике парсер SE::IxQuick был удален, а вместо него добавлен SE::Startpage с почти аналогичным функционалом
[*]Улучшена логика работы функции Get full links в SE::Baidu SE::Baidu
[*]В [IMG]https://a-parser.com/img/parsers/se-google.png[/IMG][URL=https://a-parser.com/wiki/se-google-modern/]SE::Google::Modern[/URL] реализована возможность указывать дополнительные заголовки для запросов
[*]Улучшен парсинг меток сайтов в [IMG]https://a-parser.com/img/parsers/se-yandex.png[/IMG][URL=https://a-parser.com/wiki/se-yandex/]SE::Yandex[/URL], а также добавлена поддержка новых типов меток
[*]Улучшена логика работы функции Get full links в SE::Baidu
[*]Оптимизирован алгоритм обработки подзапросов
[/LIST]
[B]Исправления в связи с изменениями в выдаче[/B]
[LIST]
[*]Улучшена работа [IMG]https://a-parser.com/img/parsers/se-youtube.png[/IMG][URL=https://a-parser.com/wiki/se-youtube/]SE::YouTube[/URL], в связи с тестированием новой верстки
[*]В [IMG]https://a-parser.com/img/parsers/se-google-translate.png[/IMG][URL=https://a-parser.com/wiki/se-google-translate/]SE::Google::Translate[/URL] переработан механизм повторных попыток, добавлена поддержка сессий
[*]Исправлен парсинг сниппетов в [IMG]https://a-parser.com/img/parsers/se-google-images.png[/IMG][URL=https://a-parser.com/wiki/se-google-images/]SE::Google::Images[/URL]
[*]Поностью переработан [IMG]https://a-parser.com/img/parsers/googleplay-apps.png[/IMG][URL=https://a-parser.com/wiki/googleplay-apps/]GooglePlay::Apps[/URL]- теперь он парсит только первую страницу результатов
[*]Исправлен парсинг мобильной выдачи в SE::Google::Modern
[*]Исправлена работа [IMG]https://a-parser.com/img/parsers/se-seznam.png[/IMG][URL=https://a-parser.com/wiki/se-seznam/]SE::Seznam[/URL] при отсутствии результатов
[*]Исправлена работа [IMG]https://a-parser.com/img/parsers/rank-linkpad.png[/IMG][URL=https://a-parser.com/wiki/rank-linkpad/]Rank::Linkpad[/URL], парсер полностью переписан
[*][IMG]https://a-parser.com/img/parsers/se-bing-translator.png[/IMG][URL=https://a-parser.com/wiki/se-bing-translator/]SE::Bing::Translator[/URL], [IMG]https://a-parser.com/img/parsers/se-duckduckgo-images.png[/IMG][URL=https://a-parser.com/wiki/se-duckduckgo-images/]SE:: DuckDuckGo::Images[/URL], [IMG]https://a-parser.com/img/parsers/se-bing-images.png[/IMG][URL=https://a-parser.com/wiki/se-bing-images/]SE::Bing::Images[/URL]
[/LIST]
[B]Исправления[/B]
[LIST]
[*]Исправлена проблема, из-за которой в некоторых случаях при запросе через API возвращался пустой массив страниц
[*]Исправлено падение скорости в [IMG]https://a-parser.com/img/parsers/net-whois.png[/IMG][URL=https://a-parser.com/wiki/net-whois/]Net::Whois[/URL]
[*]Исправлен баг в оптимизации парсеров
[*]Исправлено сохранение параметра Report period в [IMG]https://a-parser.com/img/parsers/se-yandex-direct-frequency.png[/IMG][URL=https://a-parser.com/wiki/se-yandex-direct-frequency/]SE::Yandex:: Direct::Frequency[/URL]
[*]В [IMG]https://a-parser.com/img/parsers/html-linkextractor.png[/IMG][URL=https://a-parser.com/wiki/html-linkextractor/]HTML::LinkExtractor [/URL]исправлен сбор ссылок, если в них есть перенос строки
[/LIST]
[URL=https://telegram.me/joinchat/B52bKz_xVDH2GDiEU1MPsQ][IMG]https://files.a-parser.com/img/button_a-parser_small_550.png[/IMG][/URL]












 ) - пишите
) - пишите