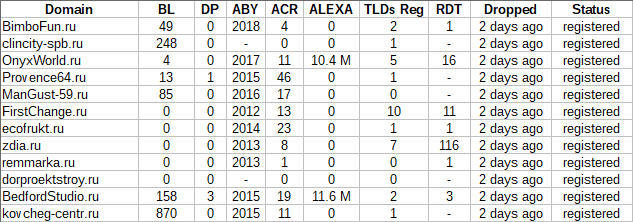
Видео урок: Массовое добавление товаров в OpenCart
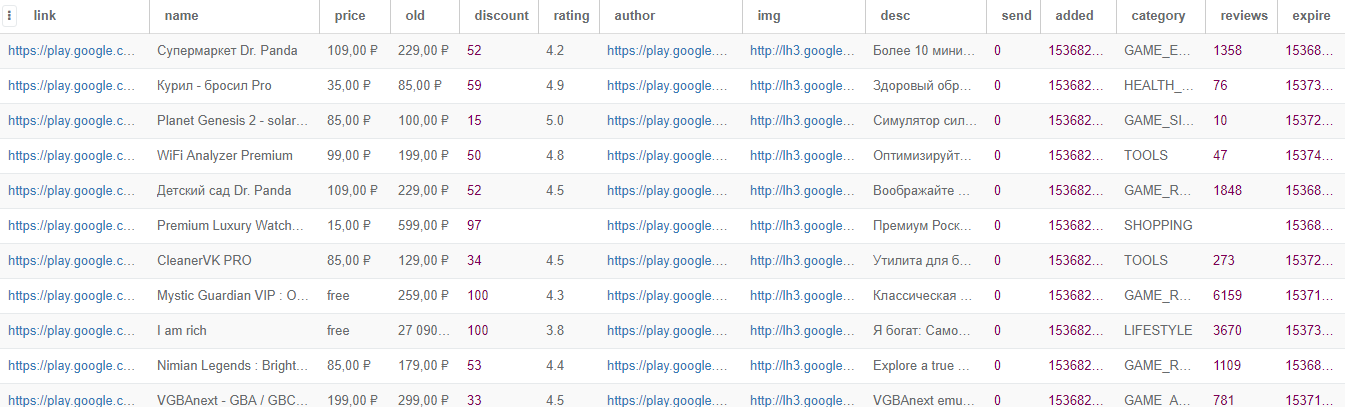
Данный парсер является примером для разработки парсера работающего с OpenCart. Решение демонстрирует возможность сбора данных о товарах из стороннего сайта и заливку их на собственный сайт на базе OpenCart через API.

В этом уроке рассмотрены:
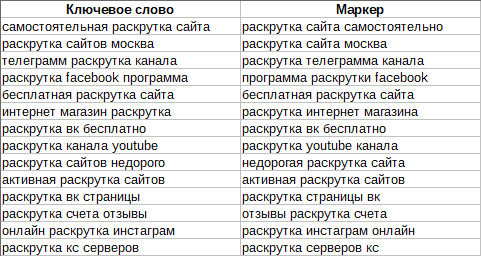
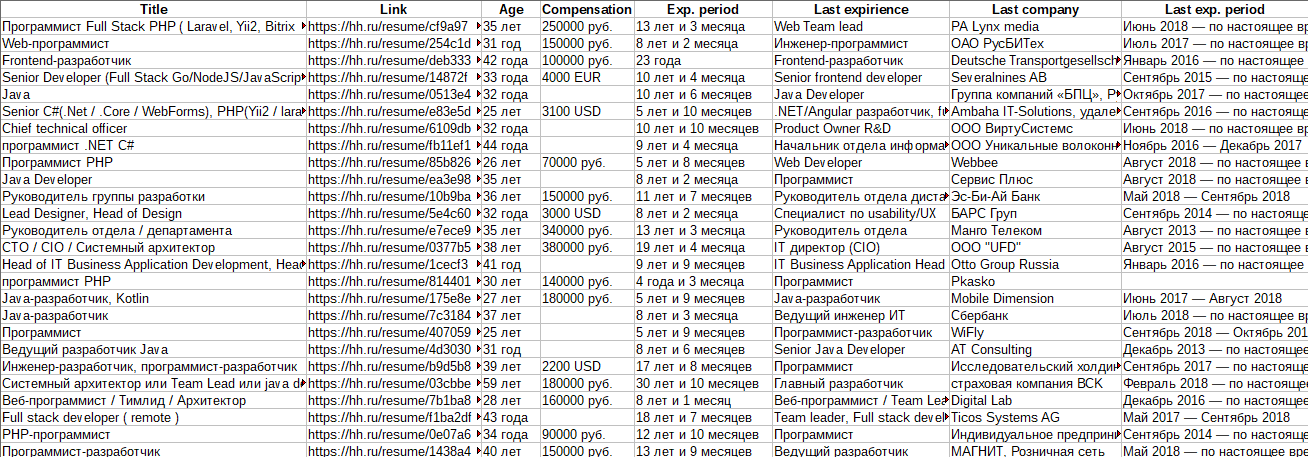
* парсинг товаров из интернет-магазина
* авторизация в OpenCart
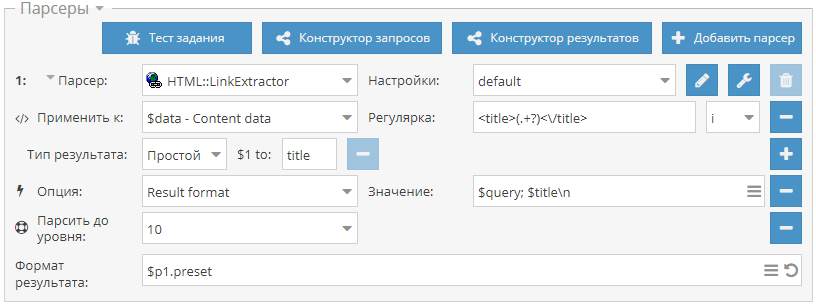
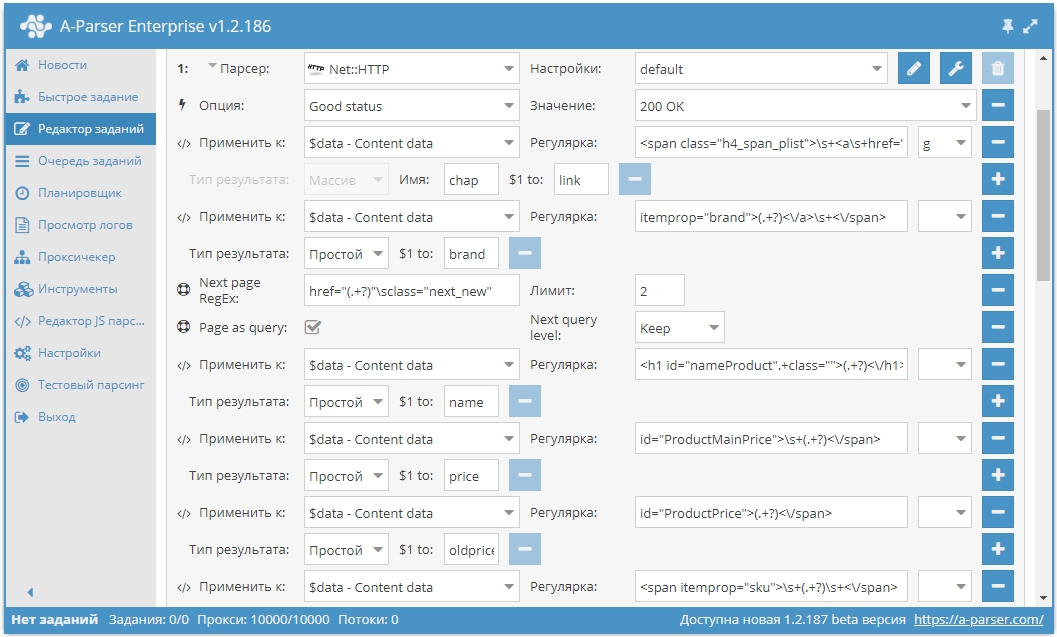
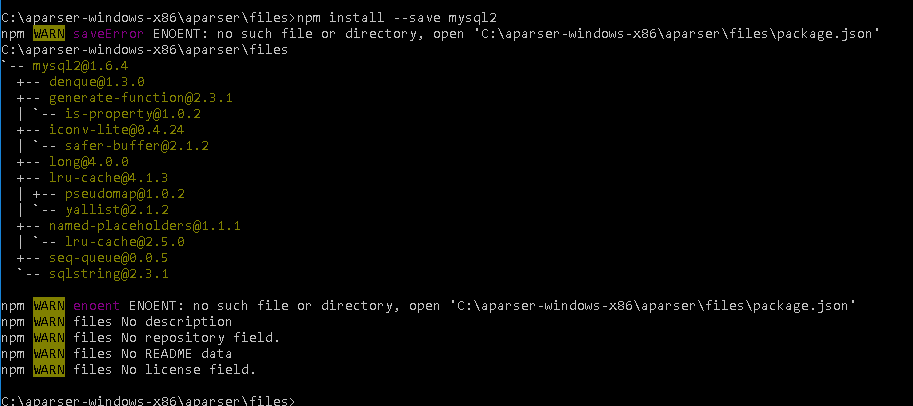
* работа с API OpenCart для публикации товаров
Статья и готовый пресет опубликованы в нашем Каталоге: https://a-parser.com/resources/302/
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
Данный парсер является примером для разработки парсера работающего с OpenCart. Решение демонстрирует возможность сбора данных о товарах из стороннего сайта и заливку их на собственный сайт на базе OpenCart через API.
В этом уроке рассмотрены:
* парсинг товаров из интернет-магазина
* авторизация в OpenCart
* работа с API OpenCart для публикации товаров
Статья и готовый пресет опубликованы в нашем Каталоге: https://a-parser.com/resources/302/
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!






 ) - отписывайтесь
) - отписывайтесь