Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
22-й сборник рецептов. В нем мы разберемся, как проверять индексацию всех страниц сайта одновременно в нескольких поисковиках, научимся парсить данные по ссылкам из выдачи одним заданием и будем искать сабдомены на сайтах. Поехали!
Получение страниц сайта и проверка индексации в Google и Яндекс
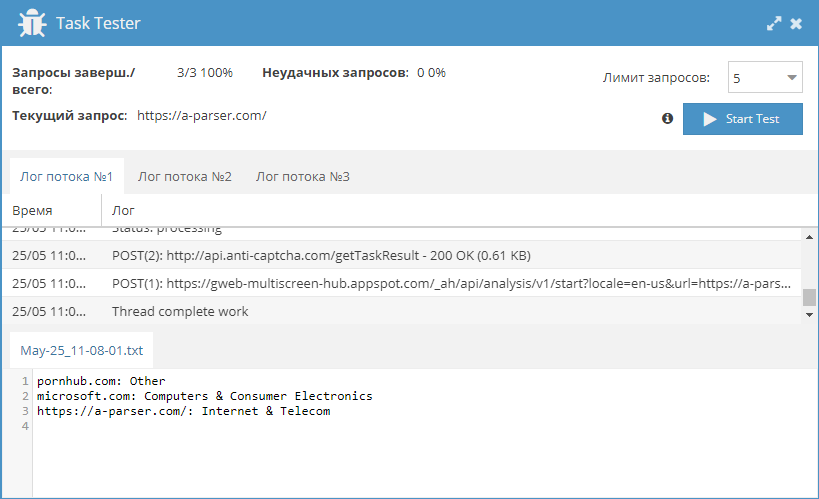
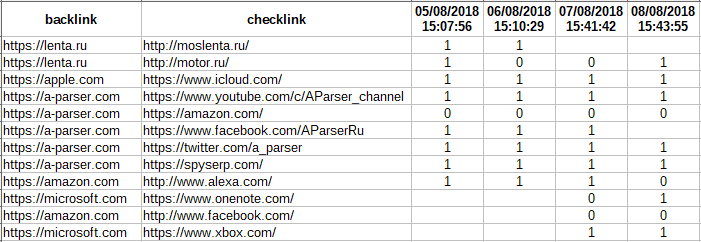
Данный пресет позволяет спарсить ссылки на все страницы сайта и одновременно проверить их на предмет индексации поисковиками (в примере Google и Яндекс, можно по аналогии добавить другие ПС). Готовый пресет и описание по ссылке выше.
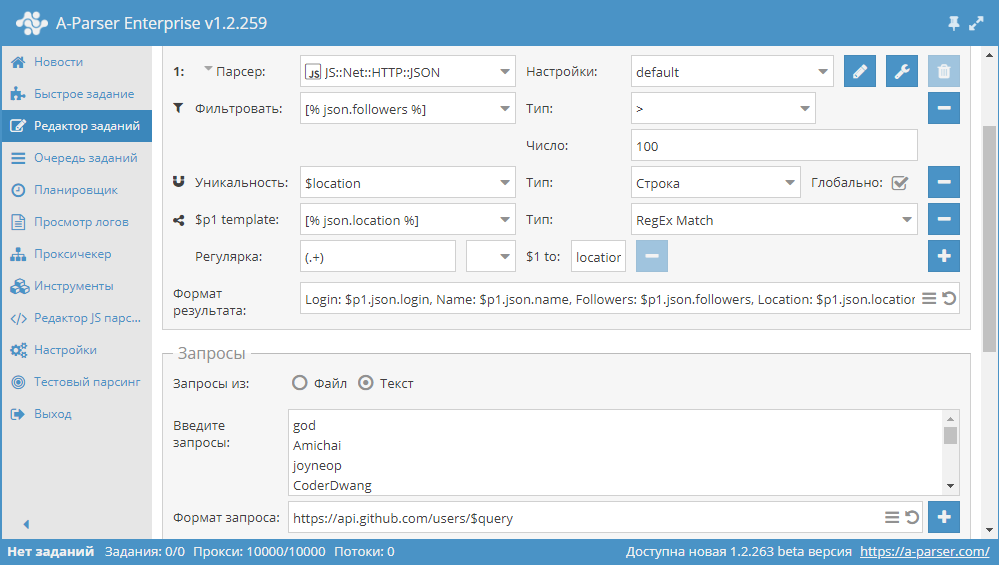
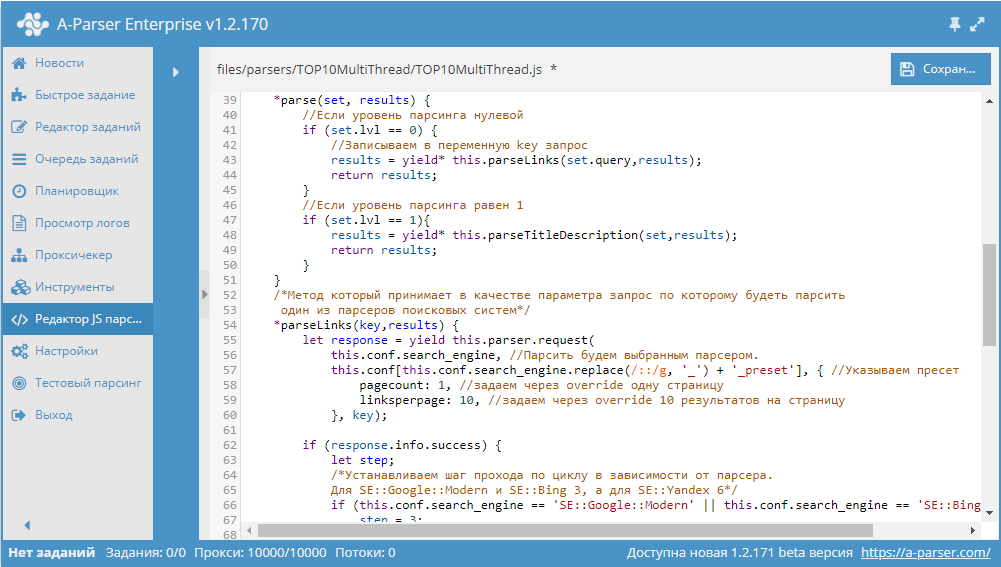
Парсим title и description для TOP10 поисковой выдачи по ключевому слову
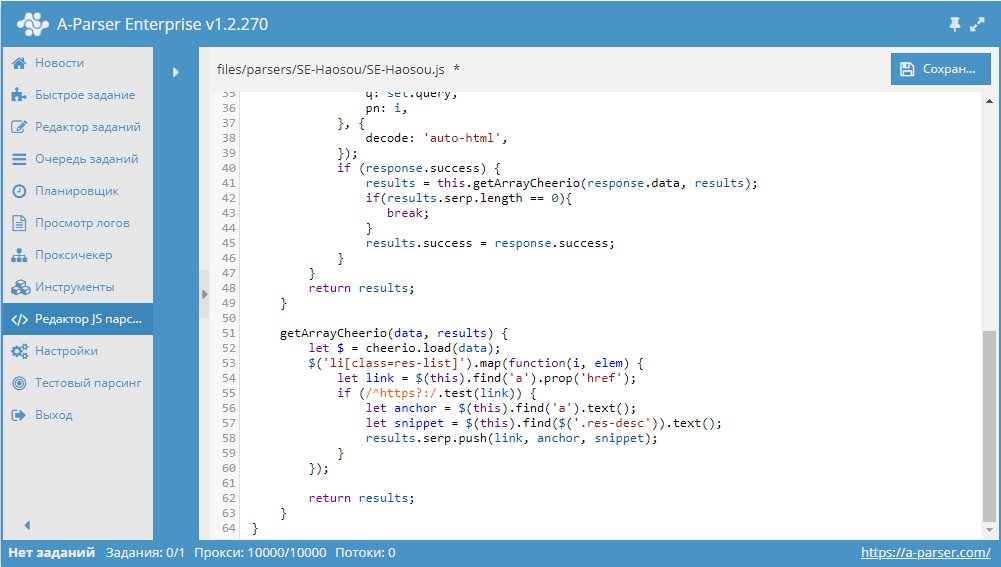
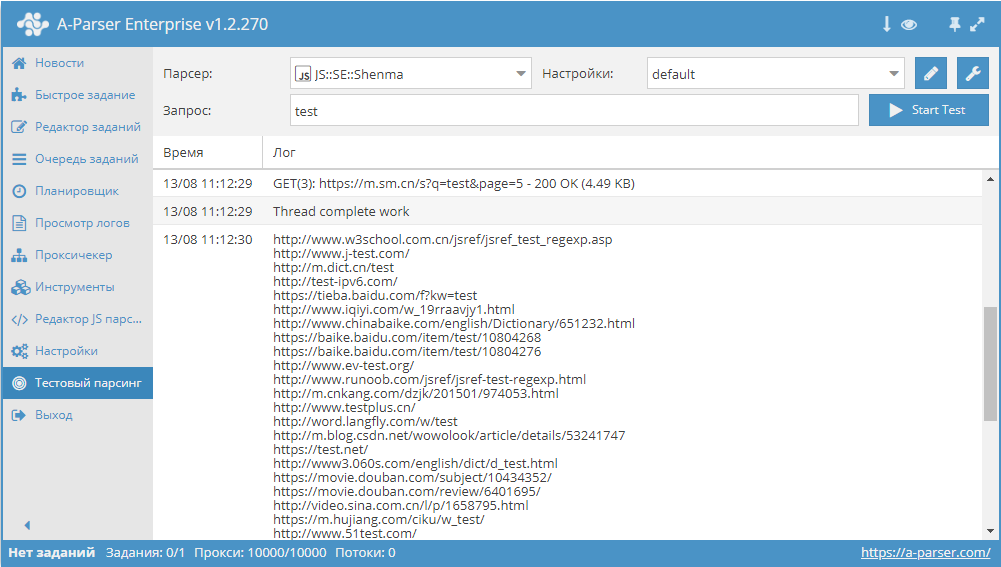
Пример использования tools.query.add в JavaScript парсерах. Данный парсер получает ссылки из выдачи, после чего собирает из каждой страницы title и description. И все это одним заданием с максимальной производительностью, благодаря многопоточному парсингу. Парсер с описанием доступны по ссылке выше.
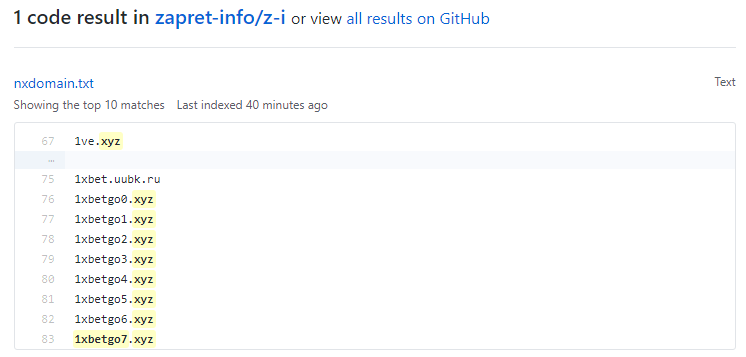
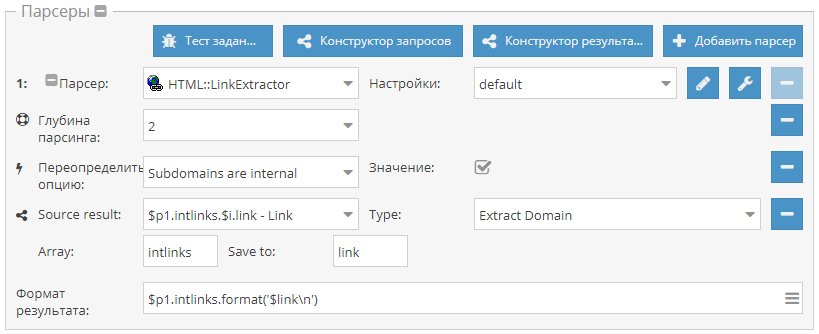
Поиск сабдоменов сайта
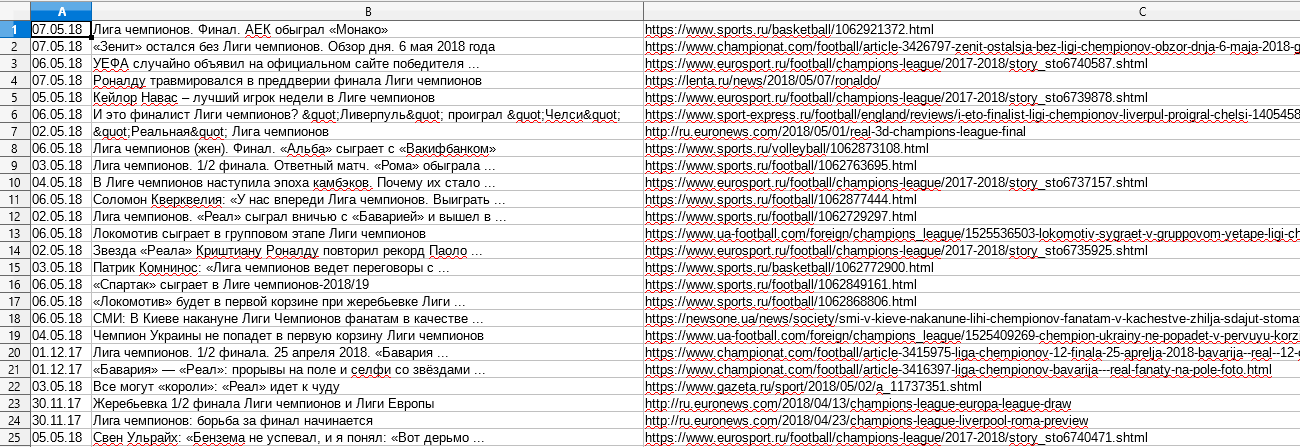
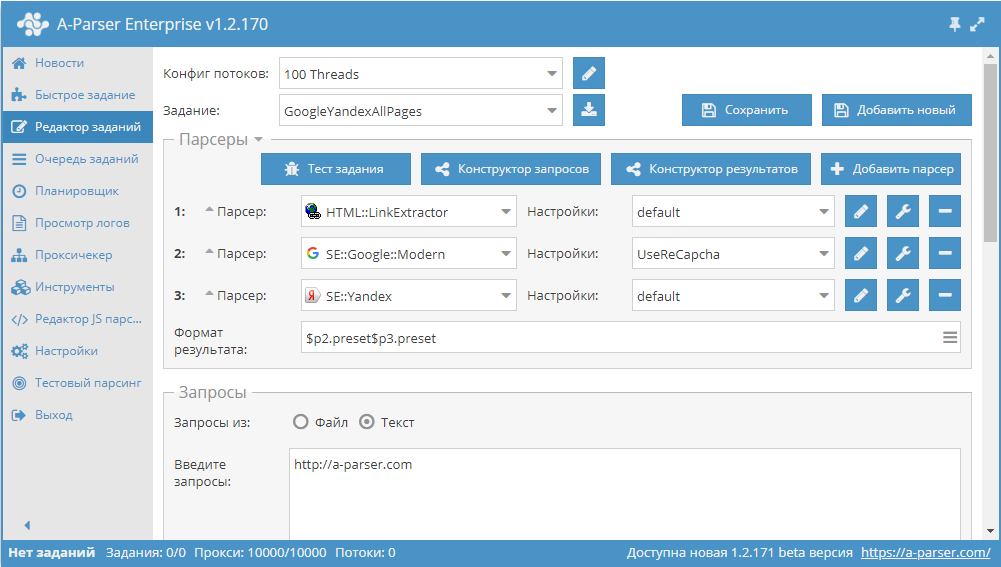
Небольшой пример, который демонстрирует, как собрать поддомены одного или нескольких сайтов. Используется
HTML::LinkExtractor и Parse to level для прохода вглубь по страницам сайта. При этом Конструктором результатов извлекаются из внутренних ссылок домены и выводятся с уникализацией по строке. Готовый пресет - по ссылке выше.
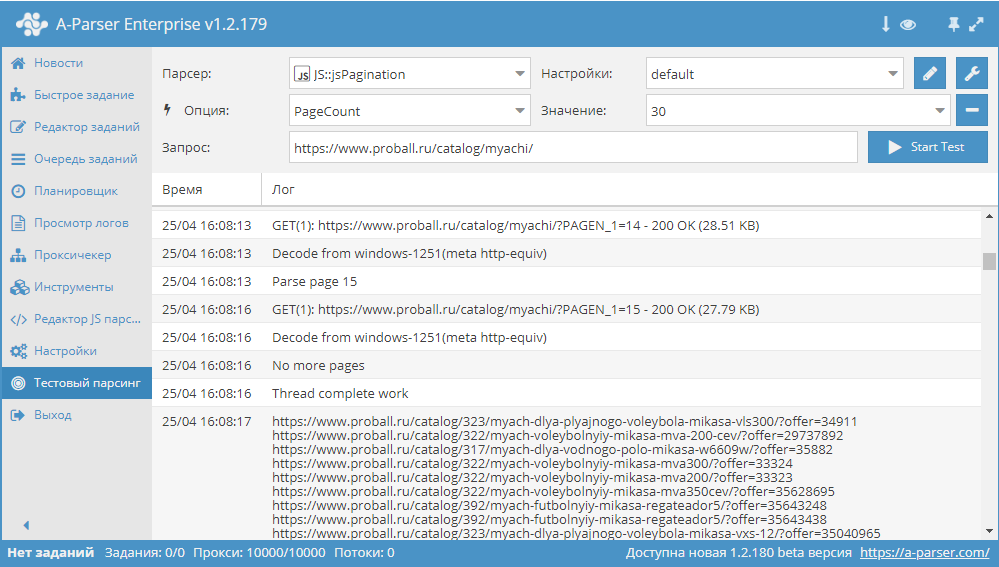
Кроме этого:
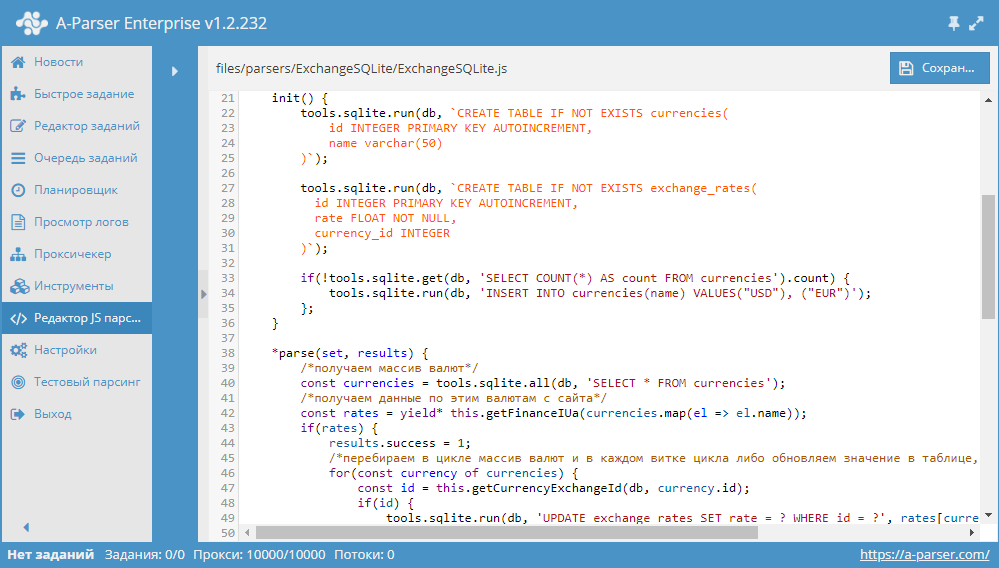
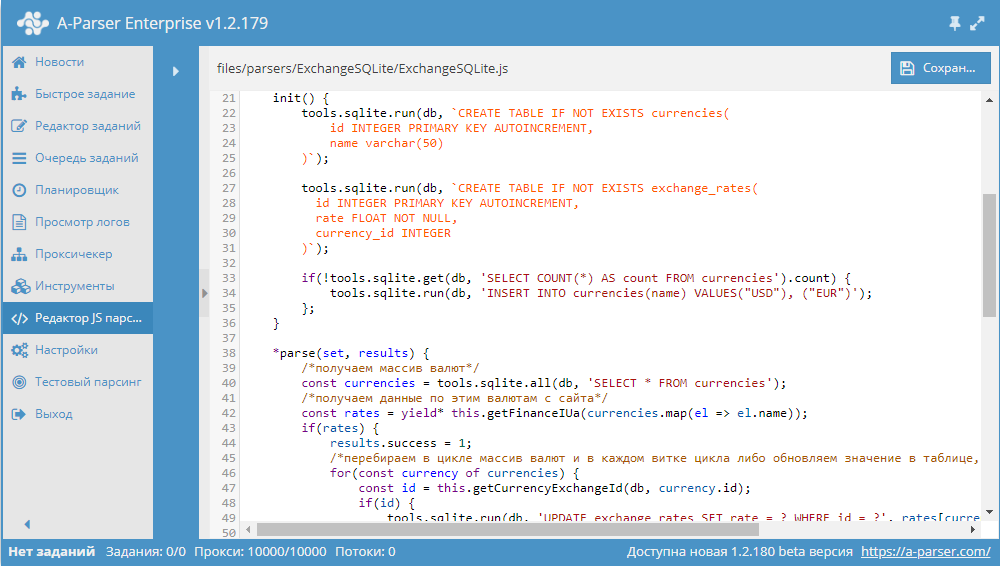
* Работа с SQLite из JavaScript парсеров - показаны все базовые возможности нового функционала по работе с SQLite
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
* Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
* Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
* Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
* Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
* Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
* Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
* Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
* Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
* Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
* Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
* Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
* Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
* Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
* Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
* Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
* Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
* Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
* Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
* Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
* Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
* Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
Сборники статей:
* Сборник статей #1: A-Parser для маркетологов, SEO-специалистов и реальный опыт работы
* Сборник статей #2: цикл статей-уроков по созданию JS парсеров
22-й сборник рецептов. В нем мы разберемся, как проверять индексацию всех страниц сайта одновременно в нескольких поисковиках, научимся парсить данные по ссылкам из выдачи одним заданием и будем искать сабдомены на сайтах. Поехали!
Получение страниц сайта и проверка индексации в Google и Яндекс
Данный пресет позволяет спарсить ссылки на все страницы сайта и одновременно проверить их на предмет индексации поисковиками (в примере Google и Яндекс, можно по аналогии добавить другие ПС). Готовый пресет и описание по ссылке выше.
Парсим title и description для TOP10 поисковой выдачи по ключевому слову
Пример использования tools.query.add в JavaScript парсерах. Данный парсер получает ссылки из выдачи, после чего собирает из каждой страницы title и description. И все это одним заданием с максимальной производительностью, благодаря многопоточному парсингу. Парсер с описанием доступны по ссылке выше.
Поиск сабдоменов сайта
Небольшой пример, который демонстрирует, как собрать поддомены одного или нескольких сайтов. Используется
HTML::LinkExtractor и Parse to level для прохода вглубь по страницам сайта. При этом Конструктором результатов извлекаются из внутренних ссылок домены и выводятся с уникализацией по строке. Готовый пресет - по ссылке выше.
Кроме этого:
* Работа с SQLite из JavaScript парсеров - показаны все базовые возможности нового функционала по работе с SQLite
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
* Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
* Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
* Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
* Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
* Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
* Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
* Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
* Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
* Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
* Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
* Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
* Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
* Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
* Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
* Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
* Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
* Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
* Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
* Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
* Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
* Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
Сборники статей:
* Сборник статей #1: A-Parser для маркетологов, SEO-специалистов и реальный опыт работы
* Сборник статей #2: цикл статей-уроков по созданию JS парсеров
 ) - отписывайтесь
) - отписывайтесь